
FAQ – Eight Questions and Answers
As SELMA is facing its last month out of 39 in total, we are wrapping up with a couple of questions and answers. Enjoy!
Was the money spent well?
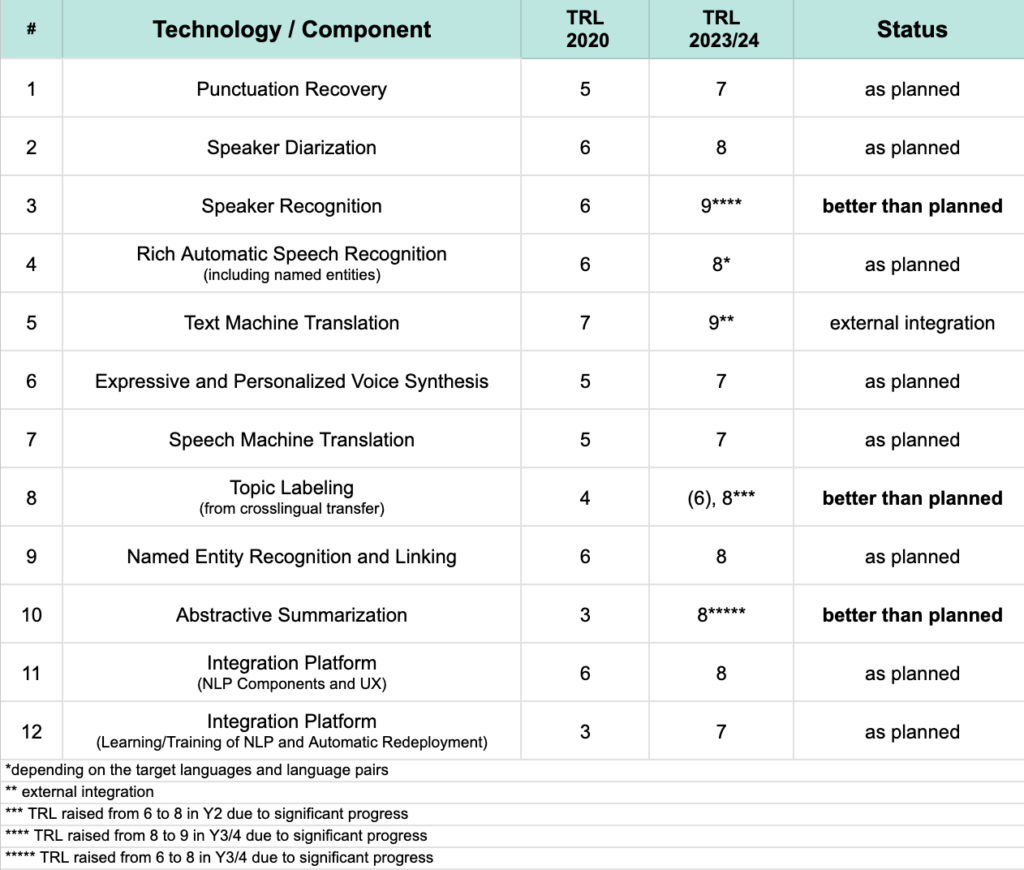
Eventually, this is up to the reviewers to decide. But this is the project in numbers: We worked on 3 Use Cases and 6 Prototypes, had 3 candidates on the EU Innovation radar, presented and demonstrated at 56 Events organized 4 user days/user group meetings, and published 31 gold standard papers, of which 1 won a prize. We wrote 39 deliverables and released 27 components, of which 7 are made available open-source. We worked with many models and experimented with and integrated different LLMs. We lifted up the Technology Readiness Level (TRL) for 10 technologies, 3 of them significantly. We developed a technology that is able to scale up to 10 million items/day. We collected 12 specific datasets and refined them, from which 2 were published for the research community.
What has SELMA done for me as a taxpayer?
With SELMA open-source (SELMA OSS), we released a platform that everybody can access and use to experiment/work with basic NLP technology: Upload a video, get it transcribed, translate it into a language of your choice (almost one hundred languages available), add voice-over and download it. Also see: Blog section below.
What has SELMA done for me as a researcher?
The SELMA output can be found on this webpage: It lists Data, Component and Prototype Releases and shows how to use them.
Please also visit SELMA on GitHub and make use of many public repositories.
What has SELMA done for me as a company?
There are two ready-to-use products. One is plain X (this is the official product website) for media production, such as transcription, translation, subtitling, and voice-over in many languages. The other one is Monitio (this is the official product website) for media monitoring, including analyzing vast amounts of multilingual content (text, audio, and video) and doing decision-making and generating reports.
Which technologies did SELMA work on?
We tried to build a system that automatically learns from a large live multilingual data stream and extends its technology readiness level. Technologies worked on include cross-lingual stream representations, named entity recognition and linking, story segmentation, news classification, clustering, and summarization; as well as on speech and language processing.
What has SELMA done in terms of ethical AI & privacy protection?
Working on and with AI comes along with identifying the boundaries of technology. Technology is supposed to help humans in the way they live and interact with each other and must not be harmful.
For SELMA this was especially valid for the diversity use case application (categorizing / labeling of people) and for cloning technologies (cloning voices). As a result of the first review we set up an ethics board and decided to reshape certain activities (e.g. no / or only research on labeling data based on Wikidata labeling, no storage of any data and no voice-cloning in the released SELMA OSS).
What has SELMA done in terms of diversity & accessibility?
There are several activities within SELMA: Diverse Datasets – we aimed to create balanced (unbiased) datasets which cover a diversity of topics and speakers (especially with regard to male and female voices). Diverse panels – during presentations and user days we strived for (binary) gender balance or at least a representation of female/ diverse speakers or participants. Diversity beyond English – in SELMA we aimed to bypass the “cultural bottleneck” by translating language directly into a target language (without being translated into English as done usually in other systems). We wrote about it in our blog (see below)
Concerning accessibility for people with disabilities, plain X is a tool that helps to create subtitles (for deaf / hearing impaired people) in many languages. One company has set up an internal roadmap committing to produce all their audiovisual content in all their languages within a three-year timespan. Also – in a still more experimental phase – the system can automatically identify and label different speakers (speaker 1, speaker 2, …) and automatically allocate colors to the subtitle text. Then different speakers (e.g. in an interview setting) can easily be differentiated while reading the subtitles.
What can I read about in the blog section of the website?
The blog feature of the homepage shows contributions to artificial intelligence and human language technologies made by consortium partners. The public at large (the people living in Europe) is the primary audience.
Here you can read about Biases in AI, Spoken Languages – Learn like a Child (about Curriculum Learning Methods), get to know about Infoboxes & Knowledge Graphs, see What we do with people, places, and organizations (about Named Entity Recognition), get A Yummy Piece of Cake (about Machine Learning Algorithms). We show Why (Counting) Diversity Matters (about Diversity in Media), and How to satisfy data-hungry machine learning (about self-supervised learning), learn what to do if you Need Computing Resources? Take a Queue Token! (about scaling), “listen” to Who Spoke When? (about Speaker Diarization), embark On the Path to the Responsible AI (about Trustworthy AI), learn Why does AI need labeled data?, dive into Introducing LeBenchmark: A Comprehensive Framework for Evaluating Self-Supervised Learning, use The SELMA Open-Source Platform and finally get personal insights with My year with plain X (about User Experience and Acceptance).
