Translating a video item from one language into another. Creating transcripts, subtitles and voice-overs. For many languages and in a collaborative manner. This is what plain X can do.
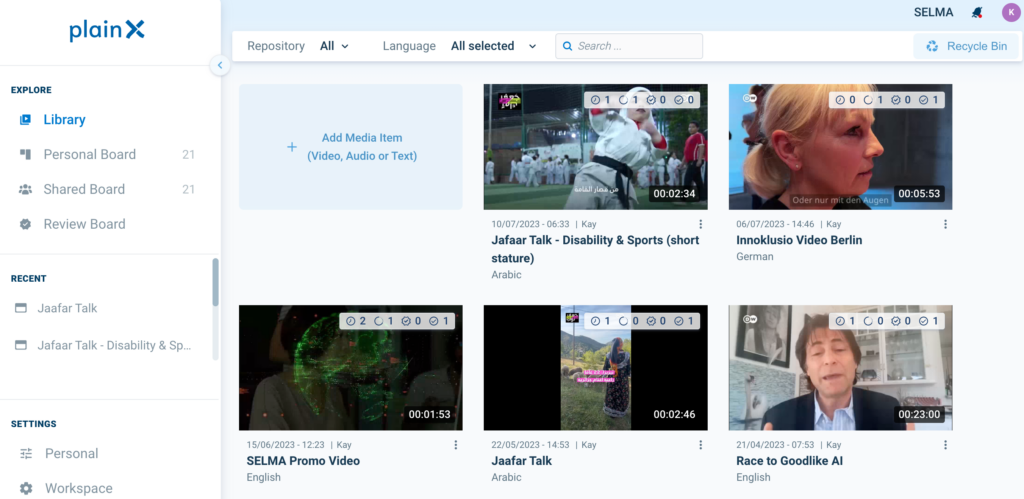
Image shows the SELMA library view of plain X with a couple of edited videos. Each video shows a bar with the status of initiated tasks. The library can be filtered by repository and languages (Menu at the top). The left bar shows Boards, recently worked on items and general settings.
SELMA contribution
- Improvement of UI for easy media localization
- Improved adaptation of voice-over to customer needs
- Improved models for transcription and translation
More
- plain X product website: https://www.plainx.com/
- plain X software (credentials needed): App plain X
Bring me to SELMA open-source Use Case