
Training large neural models for speech and language processing (NLP), requires not only a lot of data input (read here on why and here on how SELMA is handling this ) but also a lot of computing resources.
Nowadays, a fair share of computing resources are also necessary for running these models in production environments, where each incoming news item often needs to be processed through multiple NLP steps we call “NLP pipeline” – transcribed, translated, analyzed for keywords and named entities, etc.
SELMA’s solution
The SELMA platform allows for scalable execution of NLP pipelines in two kinds of production environments: continuous processing of massive text streams for media monitoring (Use Case 1) and on-demand processing of audio/video and text data for multilingual content production (Use Case 2).
The TokenQueue service, developed in the SELMA project, is a general purpose open-source platform which serves the SELMA use cases and can be used by the wider community to implement other NLP platforms and products.
TokenQueue in a (technical) nutshell
TokenQueue is a mechanism invented in the SELMA project to convert single-threaded NLP workers (Docker containers) into flexibly scalable NLP services and APIs, like those provided by MS Azure, AWS, IBM Watson, Google Cloud. While the traditional industrial solutions rely on complex middleware handling authentication, billing, queueing and scaling of the services, TokenQueue is a lightweight yet highly scalable side-car approach not intervening in the actual communication between the API client and the API server. A distinct feature of the TokenQueue approach is that multiple NLP job types (such as speech recognition, machine translation, named entity recognition, etc.) can be handled in a single TokenQueue, leading to optimal sharing of Docker or Kubernetes computing resources among the NLP jobs.
The simple idea behind TokenQueue
To achieve this functionality, TokenQueue mimics the popular customer service optimization technique widely deployed in the physical world, where an arriving customer immediately takes a queue token (ticket) with a unique number and then waits for their number to appear on the queueing screen directing them to one of the service counters. The beauty of this solution is that the number of service counters can be flexibly adjusted based on the customer influx rate (demand) without disrupting the queue.
Open-source and ready to use
TokenQueue is at the core of SELMA Basic Testing and Configuration Interface which also is an open-source software accessible at selma-project.github.io (see Figure 1) for testing, deployment, scaling and monitoring of NLP services (workers) and pipelines, like those that are being developed within SELMA for Use Cases 1 & 2 or are available from the HuggingFace repository.
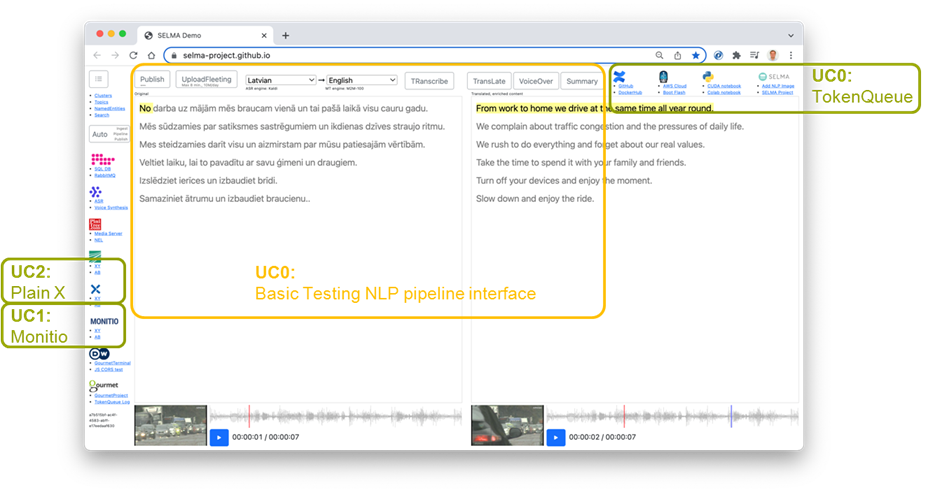
The NLP worker deployment uses a TokenQueue mechanism to deliver highly scalable NLP services like speech-to-text transcription, machine translation, and text-to-speech synthesis, all accessible via SELMA Basic Testing and Configuration Interface.
To assess this solution on a scale, the SELMA consortium will conduct a massive performance test by processing 10M news articles per day through the SELMA NLP pipelines.
Do you want to test TokenQueue for your application? Go to SELMA’s GitHub selma-project.github.io and see for yourself how it works!