
What does machine learning in the language field have to do with a cake, you might ask yourself? And how does it come that in the end we can produce better subtitles? Don’t look any further- read on!
Let them be cake!
Facebook’s AI Director Yann LeCun introduced his famous “cake analogy” on a conference in Spain. He considered intelligence as a cake: The bulk of that cake is unsupervised learning (the machine is doing the job), the icing on it is supervised learning (a bit of human intervention is needed), and finally, the cherry on top is reinforcement learning (constant feedback is the key).
This metaphor quickly became famous inside the AI community and showed that LeCun strongly advocates unsupervised learning. LeCun updated his idea in 2019 by replacing “unsupervised learning” with “self-supervised learning,” a variant of unsupervised learning where the data provides the supervision itself.
Let’s talk machine learning algorithms first
To unravel LeCun’s cake analogy, let’s look into four major types of machine learning: supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning.
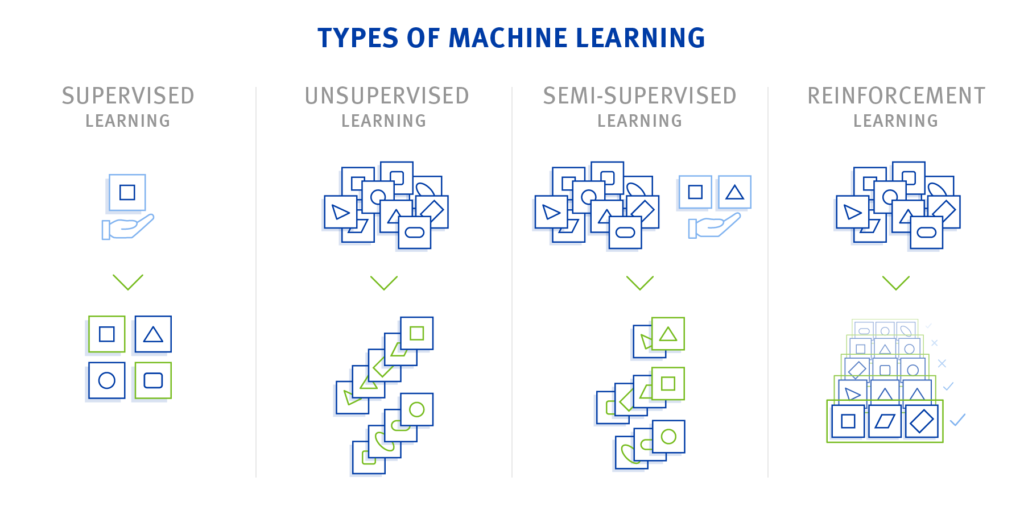
- Supervised Learning: Both input data and output results are known. The algorithm looks at the given data and tries to recognize patterns to get to the planned results. Afterward, the system can apply the learned patterns to other, unknown output data. An advantage of supervised learning is that the procedures are easy to understand. However, the preparation of the data sets needs a very high manual effort.
- Unsupervised Learning: The algorithm receives as much data as possible and searches for similarities or anomalies. The goal is to find and group similar data sets together. The advantage of this algorithm is the almost fully automated creation of models. The model learns with each data set and at the same time refines its calculations and classifications accordingly. Yet, the results are open-ended.
- Semi-Supervised Learning: The semi-supervised learning is a middle path between unsupervised and supervised learning. The difference is that only a small share of the results is known in advance, and the rest of the large data stock doesn’t have a known target variable. The main advantage of this method is the small amount of data that needs to be annotated beforehand.
- Reinforcement Learning: The system independently learns a strategy. It gets through the feedback loop and receives a positive or negative response. This method represents automated learning. It can help solve complex problems without human knowledge: If the goal is known, but the solution isn’t, the machine can often find it without human involvement! That’s why it requires a lot of training. Also, the algorithm is very adaptive and can adjust to new circumstances and even learn from other machines.
Why Data is Essential!
NLP-related machine learning made a substantial jump especially when it comes to automatically transcribed speech into text (ASR = automatic speech recognition). However, these achievements doesn’t mean that ASR is more straightforward than other NLP challenges. ASR is a natural task routinely done every day for a human (think about a listening activity from news agencies). Therefore, an extensive training set is required.
From the machine learning point of view, it is not easy to get a big data collection. A large amount of untranscribed speech data is available. Still, the potential to fully take advantage of this data has remained largely untapped. Why? Because these unlabeled data sets require skilled human annotation, for example, for audio file transcription in order to make sense. But these annotation activities are time-consuming and cost-expensive.
One of the aims of the SELMA project is to ingest large amounts of data and continuously train machine learning models. At this point, the recently developed idea known as self-supervised learning can be beneficial for our ASR systems. This approach makes the best use of unlabeled data to solve a long-standing problem in machine learning from limited training samples.
What is SELMA’s Solution?
The web is getting bigger and bigger each day. With the exponential growth of online publications and news resources (many of which are highly localized in different languages), the task of media monitoring has grown beyond human capabilities. Therefore, the SELMA project aims to mitigate this issue by automating ingestion processing and intelligence of massive streams of multilingual data.
SELMA targets to build a multilingual media monitoring system because broadcast data is very important for content providers and the public sector with various domains such as political, commercial, scientific, and many more
In this context, our initial attempts aim to fill the lack of standardization in the evaluation process for comprehensive comparisons of self-supervised models. And this challenge gets even harder with the investigation of languages other than English.
Therefore, we recently presented “LeBenchmark“, an open-source and reproducible framework for assessing self-supervision. Our experimental work includes several training schemes with large-scale and heterogeneous French speech corpora over pre-trained Wav2Vec models and a clear evaluation protocol in the complementary paper.
In the future, we aim to expand this idea, especially for low-resourced languages, for example Tamil, Bengali or Romanian. With better models in these languages, subtitles can then be produced more easily.
Edited by: Ksenia Skriptchenko
Read More:
- Big Self-Supervised Models are Strong Semi-Supervised Learners
https://research.google/pubs/pub50235 - End-to-End ASR: from Supervised to Semi-Supervised Learning
https://openreview.net/forum?id=OSVxDDc360z - Unsupervised Automatic Speech Recognition: A Review
https://arxiv.org/abs/2106.04897 - Self-Supervised Representations Improve End-to-End Speech Translation http://dx.doi.org/10.21437/Interspeech.2020-3094
- Effectiveness of Self-Supervised Pre-Training for ASR
https://doi.org/10.1109/ICASSP40776.2020.9054224 - wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations https://proceedings.neurips.cc/paper/2020/hash/92d1e1eb1cd6f9fba3227870bb6d7f07-Abstract.html