
Use of voice fingerprints in multi-speaker recordings — Speaker Diarization
A journalist’s life is made easier if questions like these can be resolved right away: What was said when? How often does the person speak, and where exactly is the audio or video? SELMA provides assistance with these activities through speaker diarization.
Speaker Diarization in a nutshell
Speaker diarization is a process that involves dividing and clustering audio data from multiple speakers into groups of segments with the same speaker identity. This is similar to keeping a diary, where events are recorded and logged. During the diarization process, salient events, such as changes in speaker turns and transitions between speech and non-speech, are automatically detected. This process does not require prior knowledge about the speakers, such as their real identity or the number of speakers in audio data.
There is a fine line between speaker diarization and other related speaker tasks like identification or change detection. The former targets to learn the voice prints of any known speaker where speakers are registered before running the model. In the latter, no such labels are given; only the boundary of change is considered for prediction. However, diarization systems predict a label whenever a new unknown speaker appears, and when the same speaker comes again, it provides the same label.
The use of speech recognition systems has increased significantly in recent years, both in terms of their scale and accuracy. In order to understand speech effectively, the ability to process audio from multiple speakers is essential. Diarization, which involves dividing an audio recording into distinct segments according to the speaker, can improve the accuracy and readability of automatic speech recognition transcriptions. When used in conjunction with speaker recognition systems, diarization can also provide the true identity of each speaker, making the transcription more valuable for applications such as meeting transcription analytics., as is seen in the following figure.
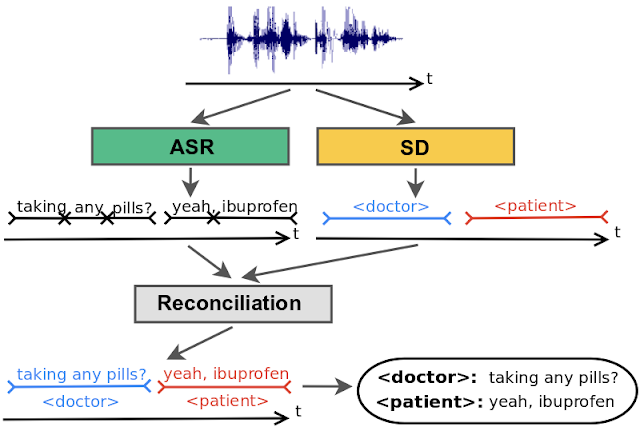
Overview of the SELMA Pipeline
To demonstrate how SELMA can assist with this work, a summarized description of the SELMA pipeline is provided in the paragraph below.
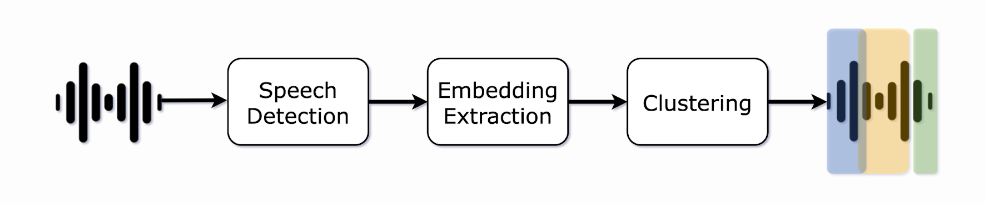
Speech Detection:
This step involves using a voice activity detector to separate speech from non-speech sounds in an audio recording. This helps to eliminate silences and other non-speech sounds from the recording. Our proposed solutions can identify speech regions with greater precision, using the timings of individual words to determine when speech is occurring.
Embedding Extraction:
In this step, small segments of the audio recording are extracted continuously. Segmentation of the audio is typically done using a small window of a few hundred milliseconds or a slightly longer sliding window. This ensures that each segment contains only one speaker. Then, the system generates neural network-based embeddings of the speech segments extracted in the previous step. However, using small segments can produce less informative results and make it difficult to determine who is speaking. Instead, we use a neural model to produce segments based on changes in the speaker. This allows for more accurate segmentation without sacrificing the ability to identify individual speakers. Finally, statistical representations called embeddings, like x-vectors, are produced by a neural model trained to distinguish between different speakers.
Clustering:
After creating embeddings of the speech segments, speaker clustering groups them according to which speaker they belong to. This is a crucial step because it assigns labels to the embeddings and indicates the number of speakers in the audio file. This process can be performed either online or offline. Online clustering involves assigning a speaker label to a vector in real time as an audio chunk is processed. This allows for immediate results, which can be useful for applications such as live captioning. However, it also means that labeling mistakes cannot be corrected. Offline clustering, on the other hand, involves assigning speaker labels to each vector after the entire audio recording is available. This allows the algorithm to go back and forth in time to find the best speaker label assignments, typically resulting in more accurate results than online clustering. In our proposed approach, we prefer to use offline clustering. Currently, the most commonly used offline technique is hierarchical clustering, which builds a hierarchy of clusters that shows the relationships between speech segments and merges similar segments. This approach can be divided into bottom-up (i.e., agglomerative) and top-down clustering. In both bottom-up and top-down clustering, two elements must be defined:
- A distance metric that measures the acoustic similarity between speech segments and is used to decide whether two clusters should be merged (in bottom-up clustering) or split (in top-down clustering).
- A stopping criterion that determines when the optimal number of clusters (speakers) has been reached.
Bottom-up clustering starts with a large number of speech segments and iteratively merges the closest segments until a stopping criterion is reached. In SELMA, we use this technique where a matrix of distances between every possible pair of clusters is computed, and the pair with the highest Bayesian information criterion (BIC) value is merged. The merged clusters are then removed from the distance matrix, and the table is updated with the distances between the new merged cluster and all remaining clusters. This process is repeated until the stopping criterion is met or all pairs have a BIC value less than zero. Top-down clustering, on the other hand, starts with a small number of clusters (usually a single cluster containing multiple speech segments) and splits them iteratively until a stopping criterion is reached.
Use Cases
Although SELMA concentrates on the creation of media content, there are other applications for this technology.
Broadcast Domain: In a typical case, there are multiple guests and hosts in broadcast radio or TV recordings, so diarization helps more precise search and analytics using keywords. Media monitoring platforms can use this to provide better insights to their customers, such as which speaker mentioned a specific keyword, and can also improve indexing, search, and navigation for individual recordings.
Podcast Hosting: Speaker diarization can detect the host and guests in podcast recordings, improving search engine optimization, search, and navigation. This is particularly useful for podcasters, as most recordings are made using a mono-channel and typically include multiple speakers.
Job Interviews: Labeling the recruiter and applicant in a hiring process can provide applicant tracking systems to split responses without listening to the audio or video. It can also enable actions such as applicant follow-ups and moving them to the next stage in the hiring process.
Streaming Platforms: Speaker diarization can extract speakers in video recordings, making automated captions more useful. Video hosting platforms can use this to improve indexing for better search and provide better accessibility and navigation for viewers.
Multi-speaker Meetings: It is possible to segment multiple speakers on the conference call recordings, which improves search and navigation on sales and support platforms. It can also trigger the performance of follow-ups and retrospective meetings.
Healthcare: Speaker diarization can automatically label the patient and doctor in appointment recordings, making them more readable and useful. This can improve the import of these recordings into database systems by providing better tagging and indexing and enabling actions such as recurrent visits.
Further Reads on the Topic
- Anguera, Xavier, et al. “Speaker Diarization: A Review of Recent Research.” IEEE Transactions on Audio, Speech, And Language Processing 20.2 (2012): 356-370.
- Basu, Joyanta, et al. “An Overview of Speaker Diarization: Approaches, Resources and Challenges.” IEEE Conference of the International Committee for Coordination and Standardization of Speech Databases and Assessment Techniques., 2016.
- Church, Kenneth, et al. “Speaker Diarization: A Perspective on Challenges and Opportunities from Theory to Practice.” IEEE Conference on Acoustics, Speech and Signal Processing, 2017.
- Park, Tae Jin, et al. “A Review of Speaker Diarization: Recent Advances with Deep Learning.” Computer Speech & Language 72 (2022): 101317.
- Al-Hadithy, Thaer M., et al. “Speaker Diarization based on Deep Learning Techniques: A Review.” IEEE International Symposium on Multidisciplinary Studies and Innovative Technologies, 2022.